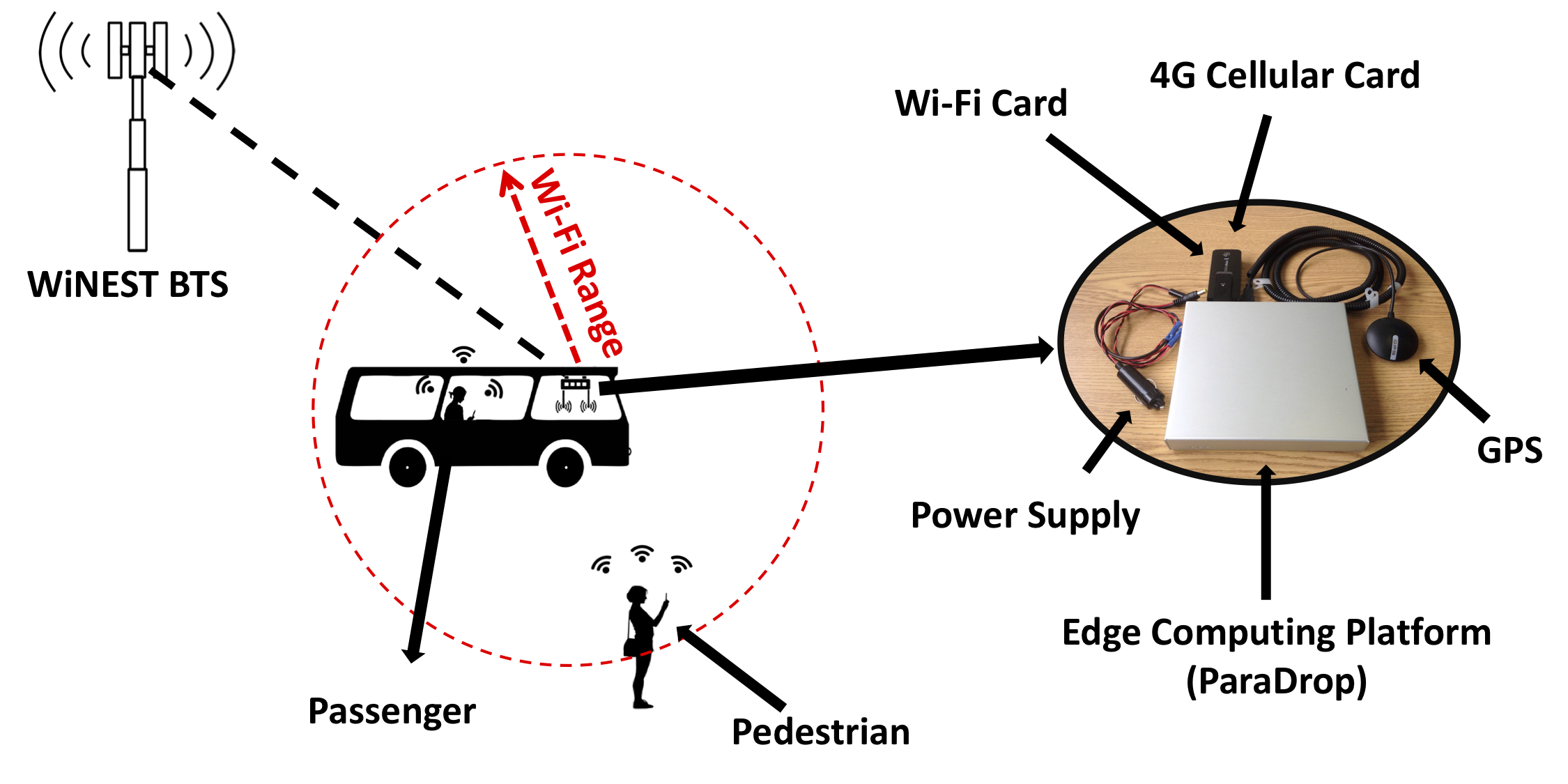
Research
In the Wisconsin Roaming Edge (WiRE) project, we attack the central research challenges within
the roaming edge, charting an aggressive path that seeks to solve critical research problems, create and
disseminate related education offerings, and, through community building and open-source software,
directly influence industry efforts in this important space.
Papers
Varun Chandrasekaran, Chuhan Gao, Brian Tang, Kassem Fawaz, Somesh Jha, Suman Banerjee (PoPET '21)
Advances in deep learning have made face recognition technologies pervasive. While useful to social media platforms and users, this technology carries significant privacy threats. Coupled with the abundant information they have about users, service providers can associate users with social interactions, visited places, activities, and preferences - some of which the user may not want to share. Additionally, facial recognition models used by various agencies are trained by data scraped from social media platforms. Existing approaches to mitigate these privacy risks from unwanted face recognition result in an imbalanced privacy-utility trade-off to the users. In this paper, we address this trade-off by proposing Face-Off, a privacy-preserving framework that introduces minor perturbations to the user's face to prevent it from being correctly recognized. To realize Face-Off, we overcome a set of challenges related to the black box nature of commercial face recognition services, and the scarcity of literature for adversarial attacks on metric networks. We implement and evaluate Face-Off to find that it deceives three commercial face recognition services from Microsoft, Amazon, and Face++. Our user study with 423 participants further shows that the perturbations come at an acceptable cost for the users.
Kan Wu, Zhihan Guo, Guanzhou Hu, Kaiwei Tu, Ramnatthan Alagappan, Rathijit Sen, Kwanghyun Park, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau (FAST '21)
We introduce multi-factor caching (MFC), a novel
approach to caching in modern storage hierarchies. MFC
subverts traditional thinking in storage caching - namely,
the sole focus on maximizing hit rate - and thus realizes
significantly higher performance than classic caching. MFC
accounts for both workload and device characteristics to make
allocation and access decisions, thus maximizing performance
(e.g., high throughput, low 99%-ile latency). We implement
MFC in Orthus-CAS (a block-layer caching kernel module)
and Orthus-KV (a user-level caching layer for a key-value
store). We show the efficacy of MFC via a thorough empirical
study: Orthus-KV and Orthus-CAS offer significantly better
performance (by up to 2x) than classic caching on various
modern hierarchies, under a range of realistic workloads.
Jingjie Li, Amrita Roy Chowdhury, Kassem Fawaz, Younghyun Kim (USENIX Security '21)
Recent advances in sensing and computing technologies have led to the rise of eye-tracking platforms. Ranging from mobiles to high-end mixed reality headsets, a wide spectrum of interactive systems now employs eye-tracking. However, eye gaze data is a rich source of sensitive information that can reveal an individual's physiological and psychological traits. Prior approaches to protecting eye-tracking data suffer from two major drawbacks: they are either incompatible with the current eye-tracking ecosystem or provide no formal privacy guarantee. In this paper, we propose Kaleido, an eye-tracking data processing system that (1) provides a formal privacy guarantee, (2) integrates seamlessly with existing eye-tracking ecosystems, and (3) operates in real-time. Kaleido acts as an intermediary protection layer in the software stack of eye-tracking systems. We conduct a comprehensive user study and trace-based analysis to evaluate Kaleido. Our user study shows that the users enjoy a satisfactory level of utility from Kaleido. Additionally, we present empirical evidence of Kaleido's effectiveness in thwarting real-world attacks on eye-tracking data.
Rishabh Khandelwal, Thomas Linden, Hamza Harkous, Kassem Fawaz (USENIX Security '21)
Online privacy settings aim to provide users with control over their data. However, in their current state, they suffer from usability and reachability issues. The recent push towards automatically analyzing privacy notices has not accompanied a similar effort for the more critical case of privacy settings. So far, the best efforts targeted the special case of making opt-out pages more reachable. In this work, we present PriSEC, a Privacy Settings Enforcement Controller that leverages machine learning techniques towards a new paradigm for automatically enforcing web privacy controls. PriSEC goes beyond finding the web-pages with privacy settings to discovering fine-grained options, presenting them in a searchable, centralized interface, and – most importantly – enforcing them on demand with minimal user intervention. We overcome the open nature of web development through novel algorithms that leverage the invariant behavior and rendering of web-pages. We evaluate the performance of PriSEC to find that it is able to precisely annotate the privacy controls for 94.3% of the control pages in our evaluation set. To demonstrate the usability of PriSEC, we conduct a user study with 148 participants. We show an average reduction of 3.75x in the time taken to adjust privacy settings as compared to the baseline system.
ChonLam Lao, Yanfang Le, Kshiteej Mahajan, Yixi Chen, Wenfei Wu, Aditya Akella, Michael Swift (NSDI '21)
Distributed deep neural network training (DT) systems are
widely deployed in clusters where the network is shared across
multiple tenants, i.e., multiple DT jobs. Each DT job computes
and aggregates gradients. Recent advances in hardware accelerators have
shifted the the performance bottleneck of training from computation to
communication. To speed up DT jobs' communication, we propose ATP, a
service for in-network aggregation aimed at modern multi-rack, multi-job
DT settings. ATP uses emerging programmable switch hardware to support
in-network aggregation at multiple rack switches in a cluster
to speedup DT jobs. ATP performs decentralized, dynamic,
best-effort aggregation, enables efficient and equitable sharing of
limited switch resources across simultaneously running DT jobs, and
gracefully accommodates heavy contention for switch resources. ATP
outperforms existing systems accelerating training throughput by up to
38%-66% in a cluster shared by multiple DT jobs.
Jiaxin Lin, Kiran Patel, Brent Stephens, Anirudh
Sivaraman, Aditya Akella (OSDI '20)
Programmable NICs have diverse uses, and there is need for a NIC
platform that can offload computation from multiple co-resident
applications to many different types of substrates, including hardware
accelerators, embedded FPGAs, and embedded processor
cores. Unfortunately, there is no existing NIC design that can
simultaneously support a large number of diverse offloads while ensuring
high throughput/low latency, multi-tenant isolation, flexible offload
chaining, and support for offloads with variable performance. This paper
presents Frenzy, a new programmable NIC. There are two new key
components of the Frenzy design that enable it to overcome the
limitations of existing NICs: 1) A high-performance switching
interconnect that scalably connects independent engines into offload
chains, and 2) A new hybrid push/pull packet scheduler that provides
cross-tenant performance isolation and low-latency load-balancing across
parallel offload engines. From both experiments performed on an 100Gbps
FPGA-based prototype and experiments that use a combination of
techniques including simulation and cost/area analysis, we find that
this design overcomes the limitations of state-of-the-art programmable
NICs.
Yifan Dai, Yien Xu, Aishwarya Ganesan, Ramnatthan
Alagappan, Brian Kroth, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau (OSDI '20)
We introduce Bourbon, a log-structured merge
(LSM) tree that utilizes machine learning to provide fast
lookups. We base the design and implementation of
BOURBON on empirically-grounded principles that we derive
through careful analysis of LSM design. Bourbon employs
greedy piecewise linear regression to learn key distributions,
enabling fast lookup with minimal computation, and applies
a cost-benefit strategy to decide when learning will be
worthwhile. Through a series of experiments on both synthetic
and real-world datasets, we show that BOURBON improves
lookup performance by 1.23x-1.78x as compared to stateof-the-art
production LSMs.
Saurabh Agarwal, Hongyi Wang, Kangwook Lee, Shivaram Venkataraman, Dimitris Papailiopoulos (ArXiV '20)
Distributed model training suffers from communication bottlenecks due to frequent model updates transmitted across compute nodes. To alleviate these bottlenecks, practitioners use gradient compression techniques like sparsification, quantization, or low-rank updates. The techniques usually require choosing a static compression ratio, often requiring users to balance the trade-off between model accuracy and per-iteration speedup. In this work, we show that such performance degradation due to choosing a high compression ratio is not fundamental. An adaptive compression strategy can reduce communication while maintaining final test accuracy. Inspired by recent findings on critical learning regimes, in which small gradient errors can have irrecoverable impact on model performance, we propose Accordion a simple yet effective adaptive compression algorithm. While Accordion maintains a high enough compression rate on average, it avoids over-compressing gradients whenever in critical learning regimes, detected by a simple gradient-norm based criterion. Our extensive experimental study over a number of machine learning tasks in distributed environments indicates that Accordion, maintains similar model accuracy to uncompressed training, yet achieves up to 5.5x better compression and up to 4.1x end-to-end speedup over static approaches. We show that Accordion also works for adjusting the batch size, another popular strategy for alleviating communication bottlenecks.
Aditya Akella Amin Vahdat Arjun Singhvi Behnam Montazeri Dan Gibson Hassan Wassel Joel Scherpelz Milo M. K. Martin Monica C Wong-Chan Moray Mclaren Prashant Chandra Rob Cauble Sean Clark Simon Sabato Thomas F. Wenisch (SIGCOMM '20)
Remote Direct Memory Access (RDMA) plays a key role in supporting performance-hungry datacenter applications. However, existing RDMA technologies are ill-suited to multi-tenant datacenters, where applications run at massive scales, tenants require isolation and security, and the workload mix changes over time. Our experiences seeking to operationalize RDMA at scale indicate that these ills are rooted in standard RDMA's basic design attributes: connection-orientedness and complex policies baked into hardware.
We describe a new approach to remote memory access - One-Shot RMA (1RMA) - suited to the constraints imposed by our multi-tenant datacenter settings. The 1RMA NIC is connection-free and fixed-function; it treats each RMA operation independently, assisting software by offering fine-grained delay measurements and fast failure notifications. 1RMA software provides operation pacing, congestion control, failure recovery, and inter-operation ordering, when needed. The NIC, deployed in our production datacenters, supports encryption at line rate (100Gbps and 100M ops/sec) with minimal performance/availability disruption for encryption key rotation.
Shimaa Ahmed, Amrita Roy Chowdhury, Kassem
Fawaz, Parmesh Ramanathan (USENIX Security '20)
New Advances in machine learning have made Automated Speech
Recognition (ASR) systems practical. ASR systems can transcribe speech
data at scale. Unfortunately, these systems pose serious privacy threats
as speech is a rich source of sensitive acoustic and textual
information. Although offline ASR eliminates the privacy risks, its
transcription performance is inferior to that of cloud-based ASR systems,
especially for real-world use cases. In this paper, we propose Preech, an
end-to-end speech transcription system which lies at an intermediate point
in the privacy-utility spectrum of speech transcription. It protects the
acoustic features of the speakers' voices and protects the privacy of the
textual content at an improved performance relative to offline
ASR. Additionally, Preech provides several control knobs to allow
customizable utility-usability-privacy trade-off. It relies on cloud-based
services to transcribe a speech file after applying a series of
privacy-preserving operations on the user's side. We perform a
comprehensive evaluation of Preech, using diverse real-world datasets,
that demonstrates its effectiveness. Preech provides transcriptions at a
2% to 32.25% (mean 17.34%) relative improvement in word error rate over
Deep Speech, while fully obfuscating the speakers' voice biometrics and
allowing only a differentially private view of the textual content.
Yuvraj Patel, Leon Yang, Leo Arulraj, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, Michael M. Swift (EuroSys '20)
We introduce the scheduler subversion problem, where
lock usage patterns determine which thread runs, thereby subverting CPU scheduling goals. To mitigate this problem, we
introduce Scheduler-Cooperative Locks (SCLs), a new family
of locking primitives that controls lock usage and thus aligns
with system-wide scheduling goals; our initial work focuses
on proportional share schedulers. Unlike existing locks, SCLs
provide an equal (or proportional) time window called lock opportunity within which each thread can acquire the lock. We
design and implement three different scheduler-cooperative
locks that work well with proportional-share schedulers: a
user-level mutex lock (u-SCL), a reader-writer lock (RWSCL), and a simplified kernel implementation (k-SCL). We
demonstrate the effectiveness of SCLs in two user-space applications (UpScaleDB and KyotoCabinet) and the Linux kernel.
In all three cases, regardless of lock usage patterns, SCLs
ensure that each thread receives proportional lock allocations
that match those of the CPU scheduler. Using microbenchmarks, we show that SCLs are efficient and achieve high
performance with minimal overhead under extreme workloads.
Kshiteej Mahajan, Arjun Balasubramanian, Arjun Singhvi, Shivaram Venkataraman, Aditya Akella, Amar Phanishayee, Shuchi Chawla (NSDI '20)
Modern distributed machine learning (ML) training workloads benefit significantly from leveraging GPUs. However, significant contention ensues when multiple such workloads are run atop a shared cluster of GPUs. A key question is how to fairly apportion GPUs across workloads. We find that established cluster scheduling disciplines are a poor fit because of ML workloads' unique attributes: ML jobs have long-running tasks that need to be gang-scheduled, and their performance is sensitive to tasks' relative placement.
We propose Themis, a new scheduling framework for ML training workloads. It's GPU allocation policy enforces that ML workloads complete in a finish-time fair manner, a new notion we introduce. To capture placement sensitivity and ensure efficiency, Themis uses a two-level scheduling architecture where ML workloads bid on available resources that are offered in an auction run by a central arbiter. Our auction design allocates GPUs to winning bids by trading off fairness for efficiency in the short term, but ensuring finish-time fairness in the long term. Our evaluation on a production trace shows that Themis can improve fairness by more than 2.25x and is ~5% to 250% more cluster efficient in comparison to state-of-the-art schedulers.
Aishwarya Ganesan, Ramnatthan Alagappan, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau (FAST '20)
We introduce consistency-aware durability or CAD, a new approach to durability in distributed storage that enables strong
consistency while delivering high performance. We demonstrate the efficacy of this approach by designing cross-client
monotonic reads, a novel and strong consistency property
that provides monotonic reads across failures and sessions
in leader-based systems. We build ORCA, a modified version
of ZooKeeper that implements CAD and cross-client monotonic reads. We experimentally show that ORCA provides
strong consistency while closely matching the performance of
weakly consistent ZooKeeper. Compared to strongly consistent ZooKeeper, ORCA provides significantly higher throughput (1.8 – 3.3x), and notably reduces latency, sometimes by
an order of magnitude in geo-distributed settings.
Jun He, Kan Wu, Sudarsun Kannan, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau (FAST '20)
We describe WiSER, a clean-slate search engine designed
to exploit high-performance SSDs with the philosophy "read
as needed". WiSER utilizes many techniques to deliver high
throughput and low latency with a relatively small amount
of main memory; the techniques include an optimized data
layout, a novel two-way cost-aware Bloom filter, adaptive
prefetching, and space-time trade-offs. In a system with memory that is significantly smaller than the working set, these
techniques increase storage space usage (up to 50%), but reduce read amplification by up to 3x, increase query throughput
by up to 2.7x, and reduce latency by 16x when compared to
the state-of-the-art Elasticsearch. We believe that the philosophy of "read as needed" can be applied to more applications
as the read performance of storage devices keeps improving.
Arjun Singhvi, Junaid Khalid, Aditya Akella, Sujata Banerjee (ArXiV '19)
It is increasingly common to outsource network functions (NFs) to the cloud. However, no cloud providers offer NFs-as-a-Service (NFaaS) that allows users to run custom NFs. Our work addresses how a cloud provider can offer NFaaS. We use the emerging serverless computing paradigm as it has the right building blocks - usage-based billing, convenient event-driven programming model and automatic compute elasticity. Towards this end, we identify two core limitations of existing serverless platforms to support demanding stateful NFs - coupling of the billing and work assignment granularities, and state sharing via an external store. We develop a novel NFaaS framework, SNF, that overcomes these issues using two ideas. SNF allocates work at the granularity of flowlets observed in network traffic, whereas billing and programming occur on the basis of packets. SNF embellishes serverless platforms with ephemeral state that lasts for the duration of the flowlet and supports high performance state operations between compute units in a peer-to-peer manner. We present algorithms for work allocation and state maintenance, and demonstrate that our SNF prototype dynamically adapts compute resources for various stateful NFs based on traffic demand at very fine time scales, with minimal overheads.
Yijing Zeng, Varun Chandrasekaran, Suman Banerjee, Domenico Giustiniano (MobiCom '19)
Understanding spectrum characteristics with little prior knowledge requires fine-grained spectrum data in the frequency, spatial, and temporal domains; gathering such a diverse set of measurements results in a large data volume. Analysis of the resulting dataset poses unique challenges; methods in the status quo are tailored for specific spectrum-related applications (apps), and are ill equipped to process data of this magnitude. In this paper, we design BigSpec, a general-purpose framework that allows for fast processing of apps. The key idea is to reduce computation costs by performing computation extensively on compressed data that preserves signal features. Adhering to this guideline, we build solutions for three apps, i.e., energy detection, spatio-temporal spectrum estimation, and anomaly detection. These apps were chosen to highlight BigSpec's efficiency, scalability, and extensibility. To evaluate BigSpec's performance, we collect more than 1 terabyte of spectrum data spanning a year, across 300MHz-4GHz, covering 400 square km. Compared with baselines and prior works, we achieve 17× run time efficiency, sublinear rather than linear run time scalability, and extend the definition of anomaly to different domains (frequency & spatio-temporal). We also obtain high-level insights from the data to provide valuable advice on future spectrum measurement and data analysis.
Robert Grandl, Arjun Singhvi, Raajay Viswanathan, Aditya Akella (ArXiV '19)
Today's data analytics frameworks are compute-centric, with analytics execution almost entirely
dependent on the pre-determined physical structure of the high-level computation. Relegating intermediate data to a
second class entity in this manner hurts flexibility, performance, and efficiency. We present WHIZ, a new analytics
framework that cleanly separates computation from intermediate data. It enables runtime visibility into data via
programmable monitoring, and data-driven computation (where intermediate
data values drive when/what computation runs) via an event abstraction. Experiments with a
WHIZ prototype on a large cluster using batch, streaming, and graph
analytics workloads show that its performance is 1.3-2x better than state-of-the-art.
Adarsh Kumar, Arjun Balasubramanian, Shivaram Venkataraman, Aditya Akella (HotCloud '19)
Over the last few years, Deep Neural Networks (DNNs)
have become ubiquitous owing to their high accuracy on realworld tasks. However, this increase in accuracy comes at the
cost of computationally expensive models leading to higher
prediction latencies. Prior efforts to reduce this latency such
as quantization, model distillation, and any-time prediction
models typically trade-off accuracy for performance. In this
work, we observe that caching intermediate layer outputs can
help us avoid running all the layers of a DNN for a sizeable
fraction of inference requests. We find that this can potentially
reduce the number of effective layers by half for 91.58% of
CIFAR-10 requests run on ResNet-18. We present Freeze
Inference, a system that introduces approximate caching at
each intermediate layer and we discuss techniques to reduce
the cache size and improve the cache hit rate. Finally, we
discuss some of the open research challenges in realizing
such a design.
Chuhan Gao, Kassem Fawaz, Sanjib Sur, Suman
Banerjee (PETS '19)
Audio-based sensing enables fine-grained human activity detection, such
as sensing hand gestures and contact-free estimation of the breathing
rate. A passive adversary, equipped with microphones, can leverage the
ongoing sensing to infer private information about individuals. Further,
with multiple microphones, a beamforming-capable adversary can defeat
the previously-proposed privacy protection obfuscation techniques. Such
an adversary can isolate the obfuscation signal and cancel it.
AudioSentry is the first to address the privacy problem in audio sensing
by protecting the users against a multi-microphone adversary. It
utilizes the commodity and audio-capable devices, already available in
the user's environment, to form a distributed obfuscator
array. AudioSentry packs a novel technique to carefully generate
obfuscation beams in different directions, preventing the
multi-microphone adversary from canceling the obfuscation
signal. AudioSentry follows by a dynamic channel estimation scheme to
preserve authorized sensing under obfuscation. AudioSentry offers the
advantages of being practical to deploy and effective against an
adversary with a large number of microphones. Our extensive evaluations
with commodity devices show that AudioSentry protects the user's privacy
against a 16-microphone adversary with only four commodity obfuscators,
regardless of the adversary's position. AudioSentry provides its
privacy-preserving features with little overhead on the authorized
sensor.
Thomas Linden, Rishabh Khandelwal, Hamza Harkous, and Kassem Fawaz (PETS '19)
The EU General Data Protection Regulation (GDPR) is one of the most
demanding and comprehensive privacy regulations of all time. A year
after it went into effect, we study its impact on the landscape of
privacy policies online. We conduct the first longitudinal, in-depth,
and at-scale assessment of privacy policies before and after the
GDPR. We gauge the complete consumption cycle of these policies, from
the first user impressions until the compliance assessment. We create a
diverse corpus of two sets of 6,278 unique English-language privacy
policies from inside and outside the EU, covering their pre-GDPR and the
post-GDPR versions. The results of our tests and analyses suggest that
the GDPR has been a catalyst for a major overhaul of the privacy
policies inside and outside the EU. This overhaul of the policies,
manifesting in extensive textual changes, especially for the EU-based
websites, comes at mixed benefits to the users.
While the privacy policies have become considerably longer, our user
study with 470 participants on Amazon MTurk indicates a significant
improvement in the visual representation of privacy policies from the
users' perspective for the EU websites. We further develop a new
workflow for the automated assessment of requirements in privacy
policies. Using this workflow, we show that privacy policies cover more
data practices and are more consistent with seven compliance
requirements post the GDPR. We also assess how transparent the
organizations are with their privacy practices by performing specificity
analysis. In this analysis, we find evidence for positive changes
triggered by the GDPR, with the specificity level improving on average.
Still, we find the landscape of privacy policies to be in a transitional
phase; many policies still do not meet several key GDPR requirements or
their improved coverage comes with reduced specificity.
John Emmons, Sadjad Fouladi, Ganesh
Ananthanarayanan, Shivaram Venkataraman, Silvio Savarese, Keith Winstein
(HotEdgeVideo '19)
Cameras are everywhere! Analyzing live videos from these cameras has
great potential to impact science and society. Enterprise cameras are
deployed for a wide variety of commercial and security reasons. Consumer
devices themselves have cameras with users interested in analyzing live
videos from these devices. We are all living in the golden era for
computer vision and AI that is being fueled by game-changing systemic
infrastructure advancements, breakthroughs in machine learning, and
copious training data, largely improving their range of
capabilities. Live video analytics has the potential to impact a wide
range of verticals ranging from public safety, traffic efficiency,
infrastructure planning, entertainment, and home safety.
Analyzing live video streams is arguably the most challenging of domains
for "systems-for-AI". Unlike text or numeric processing, video analytics
require higher bandwidth, consume considerable compute cycles for
processing, necessitate richer query semantics, and demand tighter
security & privacy guarantees. Video analytics has a symbiotic
relationship with edge compute infrastructure. Edge computing makes
compute resources available closer to the data sources (i.e.,
cameras). All aspects of video analytics call to be designed
"green-field", from vision algorithms, to the systems processing stack
and networking links, and hybrid edge-cloud infrastructure. Such a
holistic design will enable the democratization of live video analytics
such that any organization with cameras can obtain value from video analytics.
Jack Kosaian, K.V. Rashmi, Shivaram Venkataraman
(SOSP '19)
Machine learning models are becoming the primary workhorses for many
applications. Services deploy models through
prediction serving systems that take in queries and return
predictions by performing inference on models. Prediction
serving systems are commonly run on many machines in
cluster settings, and thus are prone to slowdowns and failures
that inflate tail latency. Erasure coding is a popular technique
for achieving resource-efficient resilience to data unavailability in
storage and communication systems. However,
existing approaches for imparting erasure-coded resilience
to distributed computation apply only to a severely limited
class of functions, precluding their use for many serving
workloads, such as neural network inference.
We introduce parity models, a new approach for enabling
erasure-coded resilience in prediction serving systems. A parity model
is a neural network trained to transform erasurecoded queries into a
form that enables a decoder to reconstruct slow or failed
predictions. We implement parity models in ParM, a prediction serving
system that makes use
of erasure-coded resilience. ParM encodes multiple queries
into a "parity query," performs inference over parity queries
using parity models, and decodes approximations of unavailable
predictions by using the output of a parity model. We
showcase the applicability of parity models to image classification,
speech recognition, and object localization tasks.
Using parity models, ParM reduces the gap between 99.9th
percentile and median latency by up to 3.5x, while maintaining the same
median. These results display the potential of
parity models to unlock a new avenue to imparting resourceefficient
resilience to prediction serving systems.
Bozhao Qi, Peng Liu, Tao Ji, Wei Zhao and Suman Banerjee (IEEE VNC 2018)
The way people drive vehicles has a great impact on traffic safety, fuel consumption, and passenger experience. Many research and commercial efforts today have primarily leveraged the Inertial Measurement Unit (IMU) to characterize, profile, and understand how well people drive their vehicles. In this paper, we observe that such IMU data alone cannot always reveal a driver's context and therefore does not provide a comprehensive understanding of a driver's actions. We believe that an audio-visual infrastructure, with cameras and microphones, can be well leveraged to augment IMU data to reveal driver context and improve analytics. For instance, such an audio-visual system can easily discern whether a hard braking incident, as detected by an accelerometer, is the result of inattentive driving (e.g., a distracted driver) or evidence of alertness (e.g., a driver avoids a deer).The focus of this work has been to design a relatively low-cost audio-visual infrastructure through which it is practical to gather such context information from various sensors and to develop a comprehensive understanding of why a particular driver may have taken different actions. In particular, we build a system called DrivAid, that collects and analyzes visual and audio signals in real time with computer vision techniques on a vehicle-based edge computing platform, to complement the signals from traditional motion sensors. Driver privacy is preserved since the audio-visual data is mainly processed locally. We implement DrivAid on a low-cost embedded computer with GPU and high-performance deep learning inference support. In total, we have collected more than 1550 miles of driving data from multiple vehicles to build and test our system. The evaluation results show that DrivAid is able to process video streams from 4 cameras at a rate of 10 frames per second. DrivAid can achieve an average of 90% event detection accuracy and provide reasonable evaluation feedbacks to users in real time. With the efficient design, for a single trip, only around 36% of audio-visual data needs to be analyzed on average.
Peng Liu, Bozhao Qi, Suman Banerjee (EdgeSys '18)
Deep learning with Deep Neural Networks (DNNs) can achieve
much higher accuracy on many computer vision tasks than classic
machine learning algorithms. Because of the high demand for both
computation and storage resources, DNNs are often deployed in
the cloud. Unfortunately, executing deep learning inference in the
cloud, especially for real-time video analysis, often incurs high
bandwidth consumption, high latency, reliability issues, and privacy
concerns. Moving the DNNs close to the data source with an edge
computing paradigm is a good approach to address those problems.
The lack of an open source framework with a high-level API also
complicates the deployment of deep learning-enabled service at the
Internet edge. This paper presents EdgeEye, an edge-computing
framework for real-time intelligent video analytics applications.
EdgeEye provides a high-level, task-specific API for developers so
that they can focus solely on application logic. EdgeEye does so
by enabling developers to transform models trained with popular
deep learning frameworks to deployable components with minimal
effort. It leverages the optimized inference engines from industry
to achieve the optimized inference performance and efficiency.
Ethan Young, Pengfei Zhu, Tyler Caraza-Harter,
Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau (HotCloud '19)
We analyze many facets of the performance of gVisor,
a new security-oriented container engine that integrates
with Docker and backs Google's serverless platform. We
explore the effect gVisor's in-Sentry network stack has
on network throughput as well as the overheads of performing file opens
via gVisor's Gofer service. We further
analyze gVisor startup performance, memory efficiency,
and system-call overheads. Our findings have implications for the future
design of similar hypervisor-based
container engines.
Raajay Viswanathan, Aditya Akella (ArXiV '19)
Existing distributed machine learning (DML) systems
focus on improving the computational efficiency of distributed learning,
whereas communication aspects have received less attention.
Many DML systems treat the network as a blackbox. Thus, DML
algorithms' performance is impeded by network bottlenecks, and
DML systems end up sacrificing important algorithmic and systemlevel
benefits. We present MLfabric, a communication library that
manages all network transfers in a DML system, and holistically
determines the communication pattern of a DML algorithm at any
point in time. This allows MLfabric to carefully order transfers
(i.e., gradient updates) to improve convergence, opportunistically
aggregate updates in-network to improve efficiency, and proactively
replicate some of them to support new notions of fault tolerance.
We empirically find that MLfabric achieves up to 3x speed-up
in training large deep learning models in realistic dynamic cluster
settings.
Aarati Kakaraparthy, Abhay Venkatesh, Amar
Phanishayee, Shivaram Venkataraman (HotCloud '19)
Training machine learning models involves iteratively fetching and
pre-processing batches of data. Conventionally, popular ML frameworks
implement data loading within a job and
focus on improving the performance of a single job. However,
such an approach is inefficient in shared clusters where multiple training
jobs are likely to be accessing the same data and
duplicating operations. To illustrate this, we present a case
study which reveals that for hyper-parameter tuning experiments, we can reduce
up to 89% I/O and 97% pre-processing
redundancy.
Based on this observation, we make the case for unifying
data loading in machine learning clusters by bringing the
isolated data loading systems together into a single system.
Such a system architecture can remove the aforementioned
redundancies that arise due to the isolation of data loading
in each job. We introduce OneAccess, a unified data access
layer and present a prototype implementation that shows a
47.3% improvement in I/O cost when sharing data across jobs.
Finally we discuss open research challenges in designing and
developing a unified data loading layer that can run across
frameworks on shared multi-tenant clusters, including how
to handle distributed data access, support diverse sampling
schemes, and exploit new storage media.
Edward Oakes, Leon Yang, Dennis Zhou, Kevin Houck, Tyler Harter, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau (ATC '18)
Serverless computing promises to provide applications with cost savings
and extreme elasticity. Unfortunately, slow application and container
initialization can hurt common-case latency on serverless platforms. In
this work, we analyze Linux container primitives, identifying
scalability bottlenecks related to storage and network isolation. We
also analyze Python applications from GitHub and show that importing
many popular libraries adds about 100 ms to startup. Based on these
findings, we implement SOCK, a container system optimized for serverless
workloads. Careful avoidance of kernel scalability bottlenecks gives
SOCK an 18x speedup over Docker. A generalized-Zygote provisioning
strategy yields an additional 3x speedup. A more sophisticated
three-tier caching strategy based on Zygotes provides a 45x speedup over
SOCK without Zygotes. Relative to AWS Lambda and OpenWhisk, OpenLambda
with SOCK reduces platform overheads by 2.8x and 5.3x respectively in an
image processing case study.